开刊语 在古代,“巡道”是一项重要职务:唐代派遣使者分道出巡,明代分巡道官员负责巡察各地的治理与司法事务,清代则统一称为巡道。在现代,“巡道”是我国铁路系统中不可或缺的工种,他们无论严寒酷暑,始终坚守在每段线路的最基础与最细节的巡护与检修岗位上。 本专栏依托团队成员丰富的产业实践经验,专注于互联网领域的法律与政策问题,提供深入的分析研究与解决方案。本专栏以“互联网巡道”命名,旨在实现两大目标:一是力求高站位、广视野、组合拳的撰文风格;二是秉持聚焦实操、提炼细节、久久为功的研究态度。期待能够与法律从业者们共同探讨在新技术、新形势背景下,就生成式人工智能、新业态劳动用工、公益诉讼、互联网不正当竞争、各类规范的审查等涉互联网议题提出新思路与新策略。 2025年2月11日,美国特拉华州地区法院针对汤森路透(Thomson Reuters)诉罗斯智能(Ross Intelligence)一案[1](以下简称Ross案)作出阶段性简易判决,该判决认定罗斯智能运用汤森路透旗下Westlaw产品中的案例要旨训练其自身的法律AI检索工具行为,不属于合理使用,构成著作权侵权。2024年9月27日,德国汉堡地区法院针对摄影师罗伯特・克内施克(Robert Kneschke)诉莱昂(Laion)一案[2](以下简称Laion案)作出判决,该判决认定作为非营利组织的莱昂对罗伯拍摄的部分照片实施最终可能用于AI训练的数据挖掘行为属于合理使用,不构成著作权侵权。 AI训练中的著作权合理使用问题,是当前人工智能发展过程中重要的前提性议题,上述两案分别被认为是美国和欧盟针对“AI训练著作权合理使用”领域第一案(并非“生成式人工智能训练合理使用”第一案),但显然判决指向了不同的结果。尽管美国、德国与我国的著作权合理使用法律规范与我国并不相同,但域外案例也会作为国内相关制度与裁判导向的形成提供参考。本文将在详细比对上述两案例异同的基础上,与大家共同探讨AI训练领域著作权合理使用的关键要素,最终为未来生成式人工智能训练中著作权合理使用制度的完善夯实基础。 01 两案例的基本案情 1、美国Ross案:商业公司运用竞品案例要旨分析训练法律AI检索工具不构成合理使用 原告汤森路透旗下的Westlaw是全球知名的法律检索数据库,被告罗斯智能是法律AI检索公司,其通过第三方机构LegalEase获取了数万份基于Westlaw撰写的案例要旨分析等编写的批量备忘录,并将上述内容用于训练其自身的法律AI搜索工具(非生成式AI)。值得注意的是,罗斯智能曾经希望直接接入Westlaw数据库,但因其竞争对手身份而被汤森路透明确拒绝。原告汤森路透认为被告罗斯智能侵犯了其著作权提起诉讼。2025年2月11日,美国特拉华州法院就其中2243个案例要旨的侵权问题作出阶段性简易判决,认定罗斯智能对上述案例要旨的复制等行为不属于合理使用,构成著作权侵权[3]。 图1:美国Ross案案情概览 2.德国Laion案:非盈利机构运用摄影作品组成可供生成式AI使用的数据集构成合理使用 原告罗伯特・克内施克Robert Kneschke是一名摄影师,将自己的摄影作品授权给了一家图片网站;被告莱昂Laion是一家非盈利性质的机构,其在未取得原告同意的情形下,从前述图片网站中下载了原告的摄影作品,并基于对图片地址的提取、对图片的分析等流程创建了供公众免费使用的图片索引数据集(包括图片链接及以文字形式对图片的描述但不包括图片本身),该数据集可供生成式人工智能训练使用。值得注意的是,原告授权的图片网站通过自然语言声明禁止对图片的爬虫与数据挖掘,同时有被告与部分生成式AI公司存在合作迹象(例如部分人员混同、少量资金支持等)。原告认为被告侵犯了其著作权,且不适用德国《版权法》44a、44b和60d等条款的合理使用例外。2024年9月27日,德国汉堡法院判决原告败诉,被告行为构成《版权法》60d中的科研目的数据挖掘,属于合理使用[4]。

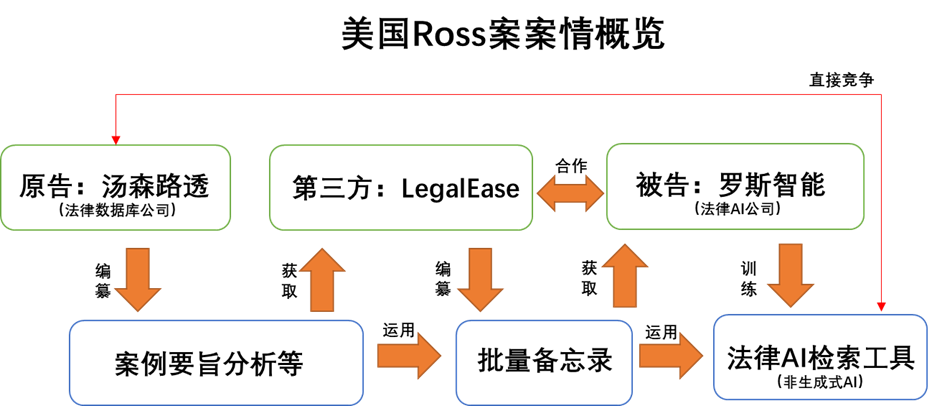
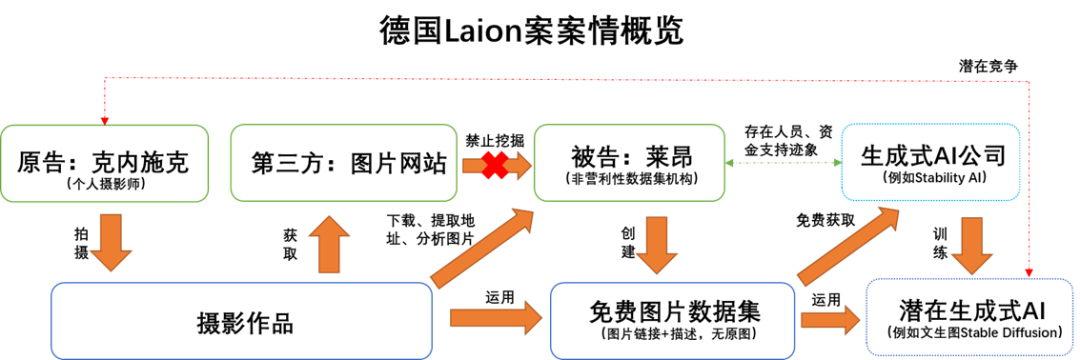
图2:德国Laion案案情概览
02
两案例的论证过程
1.美国Ross案:采用四要素审查合理使用,在两项更关键的要素中原告占优
Ross案中,法院用了一定篇幅论证案例要旨存在原创性构成作品、存在实质性相似等前提性事实,鉴于与本文“合理使用”的主题关联度较低在此不作详细阐述。在本案的合理使用审查中,法院采用了在美国被广泛适用的“四要素审查”法,即综合权衡:要素一使用行为的性质和目的、要素二被使用作品的性质、要素三被使用部分的数量和质量以及要素四使用对作品潜在市场或价值的影响四项因素。法院认为要素一和要素四是关键因素,原告全面占优;而要素二和三属于次要因素,被告虽占优但不会对案件结果造成决定性影响。具体而言:
一是被告行为属于商业性使用且“不构成转换性使用”,要素一原告占优。法院首先明确了被告行为是典型的商业性使用,但是也补充阐明需要进一步观察是否构成“转换性使用”。“转换性使用”是美国法中合理使用判断的重要因素,该原则在1994年坎贝尔案[5]中首次适用,可以被理解为:如果二次使用行为运用了原作品,但转换了原作品使用目的或方式、增加了新意义或新功能,增加了某方面的价值,那么则可能构成合理使用[6]。具体到本案中,首先被告的产品与原告相近,被告罗斯智能的产品在用户输入法律问题时,罗斯智能会返回已经撰写好的相关司法意见,不属于“生成式人工智能”,被告产品与原告数据库产品非常相近。同时,被告产品不构成代码的“中间复制”,复制代码以创建一种新产品有时可以被认为属于“转换性使用”(例如索尼案[7])然而本案中的复制的内容不是具有创新必要性与功能必要性的代码,不属于“中间复制”类的“转换性使用”。
二是原告案例要旨分析的“总创造性较低”,要素二被告占优。法院认为,案例要旨分析虽然需要一定的创造力和判断力,但是远不如“小说家或艺术家从头开始起草作品”的创造力。虽然要素二被告明显占优,但法官仍然强调被使用作品的性质这个要素在合理使用争议中“很少发挥重要作用”。
三是被告“没有直接向公众提供”案例要旨分析,而是仅用于训练,要素三被告占优。法官在判决中澄清了针对要素三“被使用部分的数量和质量”在本案中的理解,认为不宜狭隘理解为“被抄袭的案例要旨分析数量占Westlaw总的案例要旨分析”的比例,因为“从福特总统回忆录中仅抄袭300个字也可以算作抄袭了作品的核心内容”,重点还是要看复制的数量和质量是否“拿走了作品的精髓”(take the “heart” of the work)。在本案中,被告仅仅把案例要旨分析用于训练,没有直接向公众直接提供,故向公众“传达出的作品原始含义寥寥无几”(communicates little sense of the original),因此要素三的权衡中被告占据优势。
四是被告产品与原告“直接竞争且公共利益必要性不足”,要素四原告占优。法院认为,对原告竞争利益的损害不仅包括当前的也包括潜在的,原告汤森路透是否正在使用这些数据来训练自己的法律检索工具并不重要,只要证明被告的行为对原告未来潜在的法律AI检索业务市场产生影响就已足够,除非被告能够证明这些该市场不存在或不会受到影响。同时,尽管公众由获得司法判决的公共利益必要,但是被告的做法却并非是必要的。一方面司法判决本身是免费提供的,另一方面被告也完全可以自己组织力量撰写案例要旨分析,复制原告的作品并非公共利益上的必要选项。
综上,法院认为原告虽然在相对次要的要素二和三中不占优势,但在至关重要的要素一和四中明显占优,最终获得法院支持,认定不属于合理使用。
2.德国Laion案:采用三步检验法判断,认定被告属于科学研究目的的数据挖掘构成合理使用
德国汉堡法院事实上采用了欧盟和中国通用的“三步检验法”。所谓“三步检验法”包括步骤一行为属于被列举的特定情形、步骤二行为不得影响作品的正常使用、步骤三行为不得不合理地损害著作权人的合法权益[8],“三步检验法”也被我国《著作权法》[9]所容纳。在论述中,德国汉堡法院将大量篇幅用于论述第一步(是否属于被列举情形),对本案中可能涉及的德国《版权法》中关涉合理使用具体情形的第44a(临时复制)、44b(非科研目的数据挖掘)和60d(科研目的数据挖掘)[10]三个条款的适用性做了分析,并在分析具体条款适用过程中顺带完成了对步骤二和步骤三的论证。具体如下:
一是法院明确认为被告创建数据集的行为不属于德国《版权法》第44a的规定的“临时复制”。法院认为,德国法项下的临时复制,要求复制行为具体如下条件:(1)暂时性,复制必须是短暂的或偶然的。(2)附随性,复制是构成技术过程不可或缺的重要组成部分,其唯一目的是通过中介在网络中传输或合法使用作品,且没有独立的经济意义。在本案中,被告下载的图片是被单独通过另外程序删除,不具有“暂时性”,同时下载复制行为本身是“有意识且主动受控的采购行为(bewusster und aktiv gesteuerter Beschaffungsprozess)”,也不具有“附随性”。故不属于“临时复制”。
二是法院倾向认为被告不太可能符合适用德国《版权法》第44b规定的“非科研目的文本和数据挖掘”的适用条件,原因在于权利人对第三方的数据挖掘行为的自然语言禁止声明属有效。根据德国《版权法》第44b及欧盟《单一数字市场版权指令》[11]要求,只有在权利人未进行适当方式(例如机器可读形式的Robots协议)的权利保留声明时,才允许非科研性质的数据挖掘行为,本案中就此的争议焦点在于,原告的采取的自然语言权利声明是否构成“有效的权利保留”。法院虽然没有最终对第44b的适用性作出回应,但是表达了自身明确的倾向,即:自然语言的声明在当前的时代背景下也可以作为有效声明。因为不能一方面允许人工智能机器学习挖掘自然语言、提升对自然语言识别的能力,另一方面否定自然语言禁止爬虫声明的有效性。
三是法院明确认为被告免费公开数据集且并无第三方优先使用的情形下构成“非商业性使用”,符合德国《版权法》第60d规定的“科研目的文本和数据挖掘”,故符合步骤一“属于被列举的特定情形”。法院认为对于“科研”的认定应当采取相对宽容的理解,整个研发步骤包括数据采集、整理与研究等环节,本案中的数据集创建可以作为被容纳进“科研”的概念范畴。同时,从“科研”的非商业性角度看,被告将整个数据集免费公开足以证明其非商业属性。另外,对于被告可能与其他AI商业公司有联系的迹象,法院认为应当区分看待资金、人员和具体的行为,即便资金和人员有联系也不意味着每一个行为都是商业性行为。因此当被告已经将数据集免费公开时,需要转而由原告承担举证责任证明存在和其他公司的商业行为有明确关联的事实。但是,法院也另外强调如果外部私营公司对相关数据集有优先使用权则本次的结论可能发生变化[12]。
四是法院认为即便被告创建数据集的行为确实未来可能用于训练与原告有竞争性的AI,但创建数据集与AI生成内容的行为应当“分阶段”区分看待,不能无限推演创建数据集的行为后果,故符合步骤二和步骤三。法院在判决中没有采用典型的步骤一、二、三的顺次推进,而是把步骤二和步骤三的论证融合进了整个判决论述中(事实上这也是三步检验法中步骤二和三难以清晰切分的历史性固有问题[13])。首先,法院认为应当对人工智能发展中的不同步骤做明确切分(生成数据集、训练、AI生成内容),应当“分阶段”而不能视为一个整体去评估。在这个基础上,尽管最终潜在的AI生成内容的环节很可能与原告构成直接竞争可能对原告合法权益造成损害,但是这与第一步生成数据集之间的关联度有限。法院认为,从法律逻辑上看,“文本和数据挖掘可以支持训练AI,进而AI会与作者竞争”这一可能性永远无法被排除,如果把这种思路极致推演,最终会导致“文本和数据挖掘条款应永久性废除”的荒谬结论,与立法原意背道而驰。因此,尽管被告创建数据集的行为可能为训练AI提供便利并最终在AI输出内容阶段对权利人权利造成不正当损害,但仍应分阶段地点状考虑创建数据集这一行为本身,故符合步骤二和步骤三的不得影响该作品的正常使用与不得不合理地损害著作权人的合法权益。

表:美、德两件涉AI训练合理使用案解析
03
两案例中合理使用认定共性因素探析
1.“非营利性质”是判定AI训练合理使用重要考量因素
在德国Laion案中,法院在论证被告莱昂的行为符合德国《版权法》第60d规定的“科研目的文本和数据挖掘”时,明确了被告莱昂创建数据集的“非营利性质”,这也与欧盟《单一数字市场版权指令》第2条对研究机构非营利性的定义[14]及第3条科研目的的文本和数据挖掘表述[15]保持了一致。换言之,如果被告莱昂的行为具有明确的营利性质,其就只能寻求德国《版权法》第44b规定的“非科研目的文本和数据挖掘”的适用,但因权利人已作出有效禁止声明,合理使用也难以成立。
在美国Ross案中,法官明确指出:“我必须考虑至少四个合理使用因素:(1) 使用目的和性质,包括其是否为商业用途或非营利用途……”,另外有学者历史上曾统计美国法院在与合理使用相关的判决中有百分之九十以上将“非营利性质”作为合理使用的考量标准之一[16]。尽管Ross案中,法院没有对罗斯智能有非营利性的假设情形进行讨论,但显然如果罗斯智能采取了非营利模式会在四要素审查的要素一中有更大的可能获取优势,进而最终被认定为属于合理使用。
在中国法律语境下,教学与科研是一项被《著作权法》第12条明确列举的合理使用情形,而构成“科研”一般都要求限于非营利目的,如果某些文本与数据挖掘具有营利目的(无论是直接的还是间接的),则无法适用该例外[17]。虽然目前学界已经有声音主张把AI训练领域的科研行为扩张解释至以营利为目的的使用[18],但暂未形成通说。
从产业角度看,免费和开源不仅是商业策略,也有助于降低法律风险。生成式AI开源闭源之争始终存在,近期DeepSeek开源大模型的横空出世让大家意识到了与技术水准叠加的开源模型的强大势能。结合两案例,我们认为免费和开源绝不仅仅是商业策略问题,也有助于降低著作权侵权、不正当竞争等法律风险。尽管我国著作权合理使用采取的是“封闭式”的立法,不会容纳未被列举的情形,但当前生成式AI领域的法律问题尚处于相对模糊状态,其与创新、产业竞争力提升的关联性不容忽视。开源模型和模型的全部或部分免费使用虽然不能成为训练他人作品的免责“护身符”,但有可能在一定程度将降低担责的风险和赔偿数额。
2.与作品权利人竞争关系的显著程度也构成AI领域合理使用的显著影响
在美国Ross案中,被告与原告的竞争关系是清晰可见的,均提供法律检索服务,判决书中直接将被告罗斯智能界定为了原告汤森路透旗下Westlaw的竞争对手。另外,即便案发时双方在法律AI检索这一技术层面暂不存在直接竞争(汤森路透案发时未训练自有AI),但是基于双方的商业竞争关系,如无相反证据,被告罗斯智能的行为就仍然符合要素四“对作品潜在市场或价值的影响”。该案法官明确指出:“即使所有事实都对(被告)罗斯智能有利,它仍想通过开发市场替代品来与(原告)Westlaw 竞争……不论(原告)汤森路透是否使用这些数据来训练自己的法律搜索工具并不重要;对AI训练数据潜在市场的影响已经足够了”。
在德国Laion案中,双方竞争关系的链条则要更加漫长与复杂,因为缺乏直接竞争关系,原告需要承担相当长的竞争关系举证链路,且很容易被法官轻易切断。尽管无论是“三步检验法”还是“四要素审查法”中“潜在竞争”都是一项考量因素,但是相比于“直接竞争”,“潜在竞争”的概念显然更容易被攻破且存在较大的不确定性,其深层原因在于“竞争关系”最终的落脚点是对著作权人合法权益的不合理损害、作品的正常使用及潜在市场或价值的影响论证,竞争关系的明确程度将直接决定证明“损害”的难易程度。
从产业角度看,“垂直领域模型”与著作权人的竞争关系更明确,其使用他人作品训练的行为不构成合理使用的风险往往大于“通用大模型”。生成式AI领域,垂直领域模型与著作权权利人的竞争激烈程度要大于通用大模型。美国Ross案属于典型的直接竞争,即便再对技术做切分、做论证,也无法避免法律AI检索和法律数据库之间竞争关系的直观冲击力。对于各类垂直领域模型而言,与相关垂直领域的既有经营者之间的竞争关系往往相当直接,典型如小说生成模型与小说作者、短剧模型与短剧创作者、动画模型与动画创作者等。相比之下,通用大模型与垂直领域的既有经营者之间的竞争关系可能存在但未必直观,竞争关系也往往需要较多的证据进行佐证,同时通用大模型往往会被用于基座模型作为相关业态创新的基础,对于社会的创新的贡献也被认为较大,故总体的著作权风险往往要低于垂直领域模型。另外,AI企业把数据集创建工作拆分确有一定有意义。如果说Laion案中被告莱昂自身就是一家AI公司,则即便其把数据集免费公开给公众,也可能导致生成数据集、训练AI与AI输出内容三个阶段混同,最终导致案件的走向发生变化。生成式AI企业而言,目前也有两种产业链思路,一是完全自建供应链尤其是数据供应链,二是把数据集的创建工作外包。德国Laion案展示了拆分数据集创建工作的现实意义。不过需要留意,如果单纯是包装性质的“隔离层”可能很难消除风险。
3.最终用途是否为生成式人工智能可能会导致合理使用适用的不同结论。
尽管法院并没有就这个问题单独做明确论述,但是从两家法院论述的弦外之音中能够略窥一二。
在美国Ross案中,法官在判决书中两次明确表达了本案并不指向生成式人工智能,换言之隐含了法官的一种“免责声明”,即如果该案最终目的是训练生成式人工智能,则可能构成“转换性使用”进而构成合理使用最终未必构成著作权侵权。
在德国Laion案中,法官指出案涉数据集可用于人工智能,虽然法官没有对其与合理使用的联系作论述,但结合最终的判决结果与法官把数据集创建、AI训练、AI生成内容三个密不可分的阶段切分后分别评价给AI训练和生成预留空间的做法,法官也展现了其对生成式人工智能发展隐含的倾斜保护态度。
从法律理论角度看,对于生成式人工智能的考量其实回到了著作权合理使用制度的设计初衷,即作品的使用是否具有“正外部性的市场失灵(维护公共利益)[19]”,这也是美国对新技术应用“转换性使用”判断标准的根本出发点。生成式人工智能作为一项正在蓬勃发展中的新技术,存在较为明显的“正外部性”,相较于一些已经相对成熟的传统人工智能领域(例如AI搜索),至少在其“负外部性”尚不明显的现阶段,相关的作品使用更容易被公众接受未符合合理使用。

图:3:美国Ross案法院说理中明确判决不适用生成式AI

图4:德国Laion案法院说明数据集可用于生成式AI
从产业角度看,司法裁判具有时代烙印,不宜把当前对生成式人工智能的相对倾斜保护倾向视为不变的真理。如前所述,著作权合理使用需要对某项做法或技术的“正外部性”作出考量,反之如果某项做法或技术的“负外部性”显著高于“正外部性”,则相关考量的结论就非常可能发生变化。当生成式人工智能引发的社会问题显著高于其带来的“新鲜感”和“正向收益”时,合理使用的裁判尺度也可能会随之收紧,以达成著作权人权利和公共利益的平衡。
注 释:




